
DAVOS, SWITZERLAND, Jan 23, 2024 – (ACN Newswire) – Crypto Oasis, Crypto Valley, the DLT Science Foundation and Inacta Ventures Join Forces in a Groundbreaking Initiative.Crypto Oasis, Crypto Valley, the DLT Science Foundation, and Inacta Ventures united to unveil the Global Protocol Report at The Hub of Casper Labs in Davos on the 17th of January 2024. It is an exhaustive examination of DLT (Distributed Ledger Technology) protocols that intends to empower decision-makers and policymakers with invaluable insights and data points, enabling them to plot their course in the burgeoning WEB3 space confidently.

Highlights:
The report has unprecedented transparency and clarity, granular insights, and an evolving analysis of DLT protocol attributes. It will help industry experts and novices gain foundational knowledge on DLT concepts, WEB3 ecosystem infrastructure, the evolution of the Blockchain landscape, and the role of capital, talent, infrastructure, and regulations in WEB3 innovation.
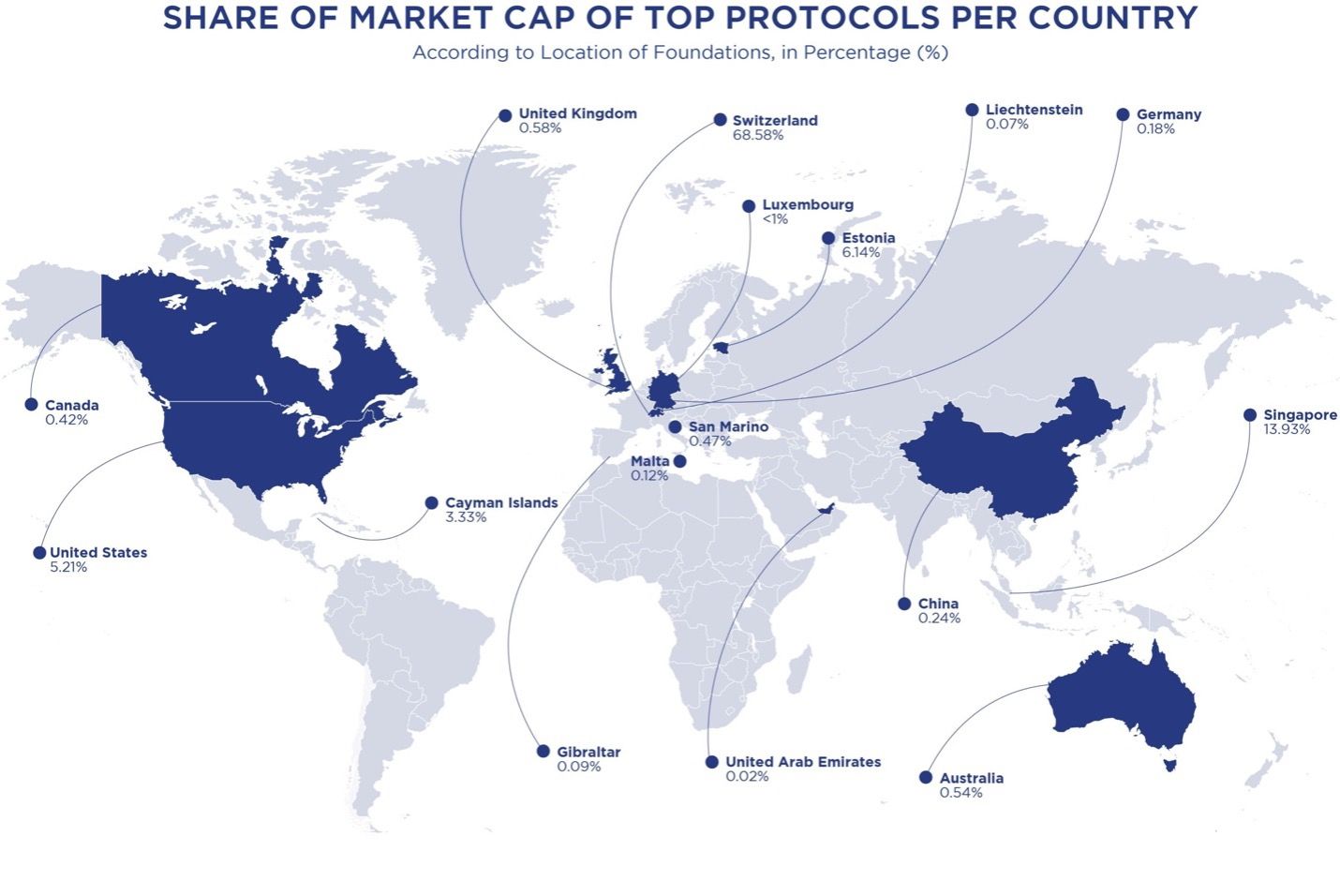
The Global Protocol Report introduces a comprehensive framework for assessing the maturity of DLT protocols, facilitating informed decision-making with concise protocol fact sheets. The report also reveals Switzerland’s dominance with 68.58% of the share of market cap of top protocols per country, followed by Singapore at 13.93%. The Global Protocol Report boasts some illustrious partners such as Coindesk Indices, Dialectic, DFINITY, Hedera, and Sui.
Unveiling the Inaugural Global Protocol Report
A Comprehensive Analysis of Blockchain Protocols
The report’s primary objective is to offer a nuanced understanding of prominent DLT protocols, exploring their strengths, weaknesses, and unique value propositions. The report has unparalleled depth and will delve into the foundational concepts of Distributed Ledger Technology. The subsequent sections delve into critical components of successful innovation, including the role of capital, infrastructure, and talent in advancing DLT protocols.
The report also addresses the intricate landscape of valuations and funding in the Blockchain sphere, focusing on critical aspects, including market cap distributions, revealing Switzerland’s dominance with 68.58% of the share of the market cap of top protocols per country, followed by Singapore at 13.93%. In terms of numbers, 20 of the leading DLT protocols are based out of Switzerland, just one short of the 21 based out of the USA. Switzerland’s leadership in the Crypto landscape is grounded in its renowned financial industry, known for security, neutrality, and privacy. This magnetism for digital asset holders has redefined the country as a centre for Crypto finance and decentralized technologies.
Ralf Glabischnig, Co-Founder of Crypto Oasis, highlighted the regulatory challenges in the Blockchain landscape, noting the significant variations globally. He emphasised Switzerland’s stability and leadership in the Blockchain domain, stating, “In the report we have explored the jurisdictions shaping the WEB3 landscape, analysing regulatory frameworks, infrastructure elements, and other factors influencing their favorability. It’s challenging how regulations can vary so greatly depending on where you are in the world, involving different regions, legal jurisdictions, and governing bodies. Switzerland, being a prominent player in Blockchain, stands as a pillar of stability and one of the most popular jurisdictions for DLT protocols. The Global Protocol Report also details valuation models and funding mechanisms so stakeholders can make informed choices and contribute to a thriving ecosystem.”
Glabischnig acknowledged that the European Union’s introduction of the Markets in Crypto-Assets Regulation (MiCA) is a notable step towards creating a cohesive framework, potentially serving as a blueprint globally. Such a regulatory landscape underscores the importance of understanding and navigating diverse legal frameworks, making the Global Protocol Report an invaluable resource.
The report delves beyond the Blockchain trilemma, i.e., the scalability, security, and decentralization trade-offs, shedding light on the emergence of side chains and second-layer solutions. This exploration unlocks new avenues for optimizing performance and maximizing user experience.
The Global Protocol Report marks a significant milestone in Blockchain research because it provides a comprehensive assessment framework for assessing the maturity of DLT protocols. This framework will allow readers to gauge the strengths and weaknesses of each of the selected protocols, facilitating comparison and identification of potential areas for improvement.
Commenting on the protocol maturity framework, Daniel Rutishauser, Partner, Head WEB3 Venture Building, Inacta Ventures said, “In our daily work, we are using our assessment framework to select the protocol that best fits the requirements for a WEB3 solution. In this report, for the first time, we give some insights into it as guidance for others to successfully build WEB3 solutions. The Global Protocol Report is a game-changer for understanding DLTs. This is a data-driven roadmap with a clear framework for assessing protocol maturity that will empower decision-makers and policymakers in the intricate world of Blockchain technology. By shedding light on the technical complexities and financial dynamics of DLT protocols, the report paves the way for a more informed and responsible WEB3 future.”
Each of the selected Blockchain protocols has been researched and graded on various attributes, including governance, performance efficiency, reliability, security, maintainability, usability, and adoption. The fact sheets for each protocol in the second part of the report include facts and figures such as the consensus mechanisms, transaction speeds, Tokenomics, etc.
“The Global Protocol Report is a critical resource to understand the Blockchain landscape, offering a unique lens on the evolution of DLT protocols. It not only tracks the advancements in Blockchain technology but also provides a framework for assessing protocol maturity. Our collaboration in this report underlines the DLT Science Foundation’s dedication to fostering informed decision-making in the Blockchain arena, especially as we navigate the complexities of scalability, security, and decentralisation. This report is an essential guide for anyone committed to understanding and shaping the future of WEB3.” said Paolo Tasca, Co-Founder and Chairman of the DLT Science Foundation.
A unique aspect of the Global Protocol Report is its commitment to being an evolving and dynamic resource. Regular updates will incorporate new trends and developments, allowing for a time series analysis and showcasing major shifts in the protocol landscape over time. This ensures users have access to a resource that remains current, providing a valuable lens for assessing the evolving maturity and potential of individual protocols.
“We are excited to be included in the first edition of the Global Protocol Report, providing digital asset market intelligence through meticulously crafted research”, said Alan Campbell, President of CoinDesk Indices. “As a firm dedicated to rigorous research and thoughtfully constructed indices, we are pleased to partner with Crypto Oasis and Inacta Ventures as they further the global Crypto economy through education.”
The Global Protocol Report stands as a beacon of clarity in the ever-shifting landscape of WEB3. This essential resource promises to fuel the development of a more robust and thriving DLT ecosystem. The Global Protocol Report is an invitation to explore, understand, and shape a future powered by distributed ledger technology.
Download the Global Protocol Report today and embark on your own journey of discovery within the ever-evolving Blockchain landscape.You can download the report at https://cryptooasis.ae/globalprotocolreport2024/
About Crypto Oasis
The Crypto Oasis is a Middle East-focused Blockchain ecosystem supported by initiators of the Crypto Valley Switzerland. The core elements needed for its development are Talent, Capital, and Infrastructure. The Ecosystem’s stakeholders include Investors & Collectors, Start-Ups & Projects, Corporates, Education & Research Institutions, Service Providers, and Government Entities & Associations. Crypto Oasis is the leading Blockchain ecosystem in the world. Today it is the fastest growing, with more than 1,800 organisations in the UAE alone. www.Cryptooasis.ae
About Crypto Valley
The Crypto Valley Association is a Swiss-based independent with the mission of building the world’s leading Blockchain and Cryptographic technologies ecosystem. The CVA is powered by its eleven Working Groups and by its driven members. The main purpose of the Association is fostering collaboration, driving adoption of digital assets and connecting startups, established enterprises through networking, research, policy recommendations, and its yearly flagship conference – the Crypto Valley Conference.Learn more through https://members.Cryptovalley.swiss/
About Distributed Ledger Technology Science Foundation
DLT Science Foundation is an international nonprofit organisation committed to help create a more equitable society — one that fully utilises DLT, Blockchain and related WEB3 technologies by fostering an open, sustainable innovation ecosystem of leaders, science fellows and developers.
About Inacta Ventures
As a network enabler and execution company, we are dedicated to connecting startups and corporates in the WEB3 space. With a strong and proven network of partners and advisors, we offer a comprehensive range of services to help our clients navigate the complex world of Blockchain and WEB3. Our services include advisory, venture building, smart capital and community building. With our ecosystem, we offer a range of high-quality services to help our clients achieve their goals and succeed in the WEB3 space. Let us help you turn your WEB3 idea into reality.https://inacta-ventures.com/
About CoinDesk Indices
CoinDesk Indices (CDI), a subsidiary of CoinDesk, has been the leading provider of digital asset indices by AUM since 2014. CDI is driven by research and a desire to educate the marketplace and empower investors. CoinDesk is the most trusted media, events, indices and data company for the global Crypto economy.
For more information contact:
Faisal Zaidi
Crypto Oasis
[email protected]
+971 55 200 0840
Visit us on social media:
Twitter
LinkedIn
YouTube
Other
Topic: Press release summary
Source: Crypto Oasis
Sectors: Crypto, Exchange, Blockchain Technology, FinTech, NFTs, Metaverse, Games

http://www.acnnewswire.com
From the Asia Corporate News Network
Copyright © 2024 ACN Newswire. All rights reserved. A division of Asia Corporate News Network.
Source : ACN Newswire